Noindex Tag
What is a Noindex tag?
A “noindex tag” is an on-page directive instructing search engines not to index the page. It is one of the methods of blocking indexing on a website.
Here “tag” refers to the meta tag placed in the <head> section. However, “noindexing” can also be done using the HTTP response header via X-Robots-Tag.
Here’s an example of the most common method, i.e., the “noindex” meta tag’s placement in the head section:
<!DOCTYPE html>
<html><head>
<meta name="robots" content="noindex" />
(…)</code>
And here’s an example of using an X-Robots-Tag in the HTTP header:
HTTP/1.1 200 OK
(…)
X-Robots-Tag: noindex
(…)
The X-Robots_Tag can be used for non-HTML resources like PDFs, videos, and images.
Why is the “noindex” tag important?
Using the “noindex” tag effectively prevents the pages and resources from appearing in the search results.
These can include “thank you” pages, ads landing pages, thin or low-quality pages, blog archives, author and tag pages, login pages, etc.
However, if misused, the “noindex” tag can do harm to your website.
Best practices for using “noindex”
If you’ve decided that you need to “noindex” some pages, here are some of the best practices.
1. Make sure the page is not disallowed in robots.txt file
The pages disallowed in robots.txt can still get into the search engine index. Sometimes the pages can be indexed without crawling their content.
And when you add a “noindex” tag to a page, Google must re-crawl the page to read this directive. So you must make sure that the page is accessible to the crawler.
2. Long-term “noindex” leads to “nofollow”
You should note that the pages with the “noindex” tag in the long term will not pass any link equity to other pages.
John Mueller from Google explained that when Google sees the “noindex” for a long time, the pages are removed entirely from the index, and the links on them will no longer be crawled.
So, even if the page is “noindex, follow,” it wouldn’t be different from “noindex, nofollow” in the long run for Google.
However, what “long-term” here means is not evident, and that depends on multiple factors.
3. Don’t use “noindex” on duplicate content
Using the “noindex” tag is not the best way to deal with duplicate content on your website.
To consolidate duplicate pages on your website, use canonical tags. Proper canonicalization instructs search engines to index only the main (canonical) version of the page. But the link signals from all non-canonical versions of a page will be consolidated, thereby giving a boost to the canonical version.
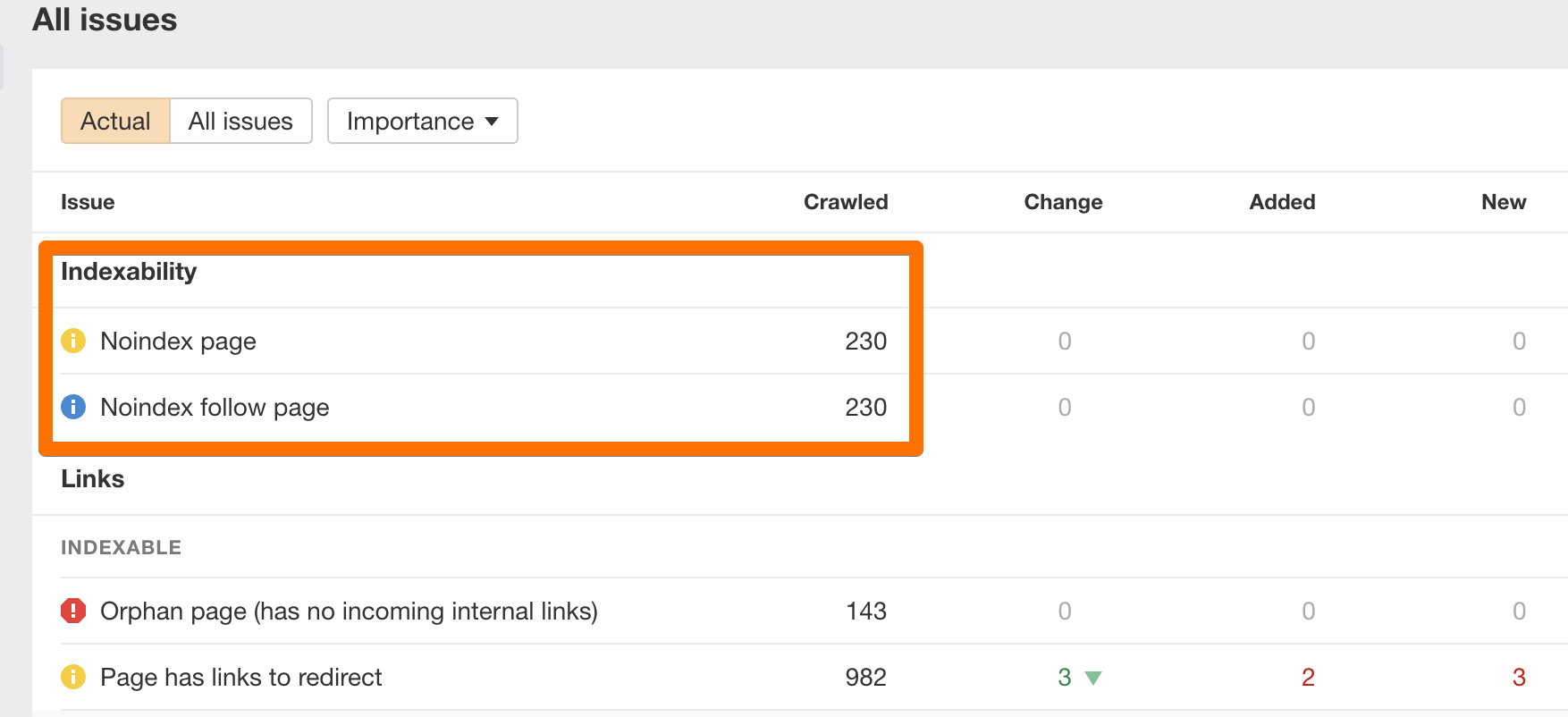
4. Regularly monitor your website for SEO issues
Monitoring your website for SEO issues can save you from traffic losses related to indexability. For example, pages or whole website sections could be “noindexed” by mistake.
You can use Ahrefs’ Site Audit tool to keep an eye on the SEO health of your site.
FAQs
Do noindexed pages pass PageRank?
Noindexed pages will be removed from Google’s index. Eventually, Google will stop crawling these pages, and thus PageRank (link juice) won’t be passed to other pages.
Using “noindex, follow” directive won’t help.
<meta> tag or X-Robots-Tag - which is better for noindex?
Both <meta> tag and X-Robots-Tag work equally well. However, it’s much easier to add a “noindex” meta tag to the page, especially in WordPress.
How to “noindex” a page in WordPress?
You can add a “noindex” tag to any page in WordPress using the Yoast plugin. Here’s how you can do it:
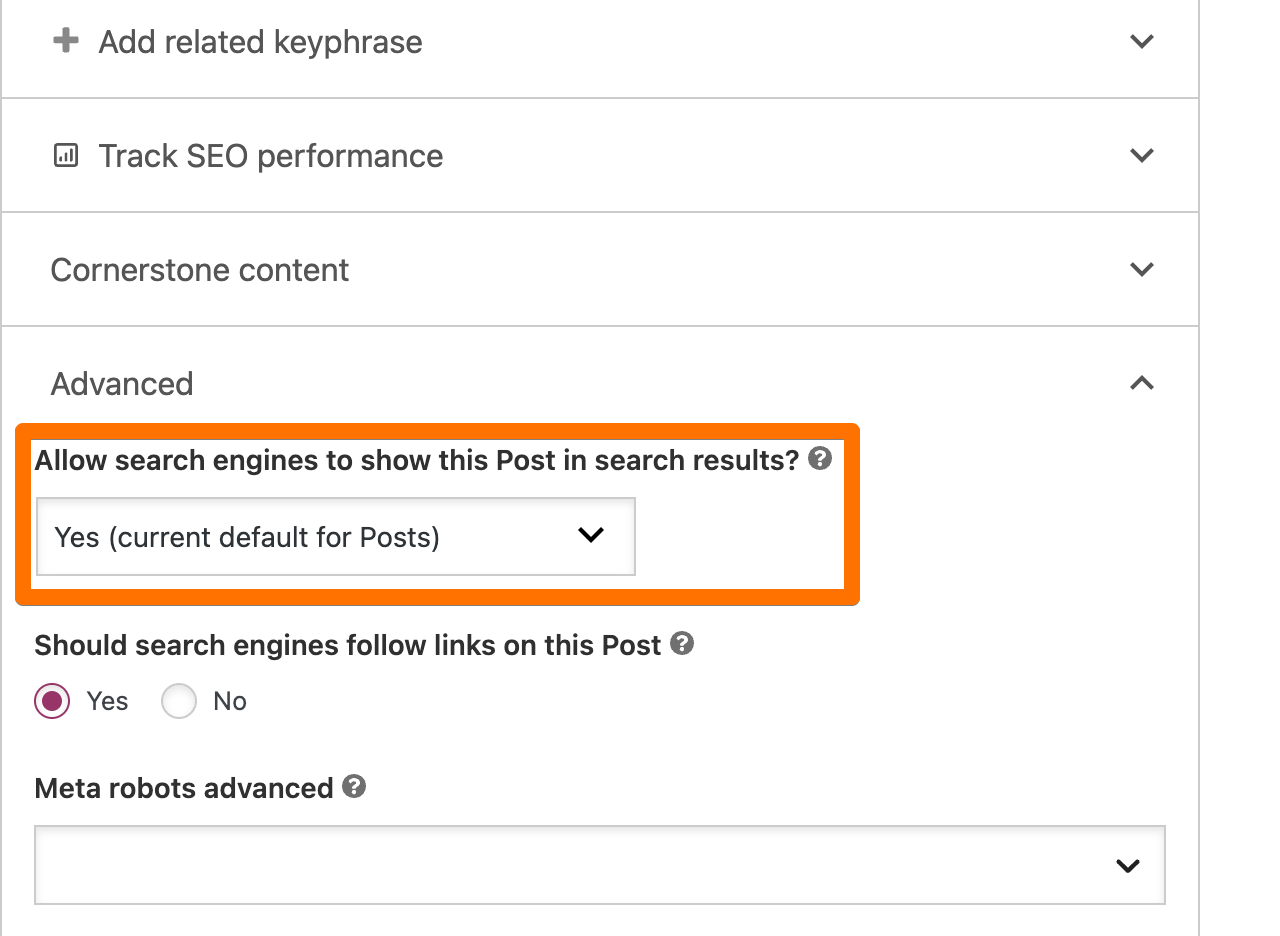
- In WordPress editor, scroll down to the “Yoast SEO” section.
- Click on “Advanced.”
- In “Allow search engines to show this post in search results?”, change the answer from “Yes” to “No.”
It will take some time for the “noindex” tag to be effective and for the page to disappear from the search results.