Googlebot
What is Googlebot?
Googlebot is the name given to Google’s web crawlers that collect information for various Google services, including their search index.
It has two main versions: Googlebot Desktop and Googlebot Smartphone. With the mobile-first indexing, Googlebot Smartphone became the primary crawler powering Google’s search index.
So, how does Googlebot work?
Googlebot constantly crawls the web to discover new pages, sends the pages for processing to add them to the search index, and re-crawls pages to look for new/updated information.
During this process, Googlebot strictly follows the rules in robots.txt files and directives for crawlers on pages and links.
Why Is Googlebot important?
Googlebot is one of the main tools that power the whole Google search engine. Without it, the entire search (and thus SEO) would not exist. If Googlebot didn’t crawl a website, it wouldn’t be indexed and visible in the results.
Thus, SEO professionals and webmasters need to understand how Googlebot works. Besides, it’s important to ensure the crawler accesses the site properly without any crawlability or discoverability issues.
Best practices for a crawl-friendly website
If you want Googlebot to crawl your website properly and get the pages indexed, you must ensure certain things are in place. Since it is not a one-time event, below are some of the best practices to follow regularly to maintain a crawl-friendly website.
1. Check your robots.txt file
Robots.txt file on the website allows you to control what is crawled. It communicates with bots using crawler directives.
You need to ensure that your robots.txt file doesn’t disallow Googlebot to crawl the pages/sections of your website that you want to be indexed.
Next, look for any errors in the file using robots.txt testing tools.
You should ensure that the robots.txt is accessible to Googlebot, i.e., it is not blocked on the server level.
2. Submit the sitemaps
Submitting sitemaps is the simplest way to let Google know which pages you want to be crawled and indexed.
Creating sitemaps isn’t tricky if you use any popular SEO plugin on WordPress, such as Yoast or Rank math. They will automatically create sitemaps for you, which you can submit.
The generated URL will look like this: yourdomainname.com/sitemap_index.html
To submit a sitemap URL manually, you need to visit Google Search Console and click on “Sitemaps” under the “Index” section in the main menu.

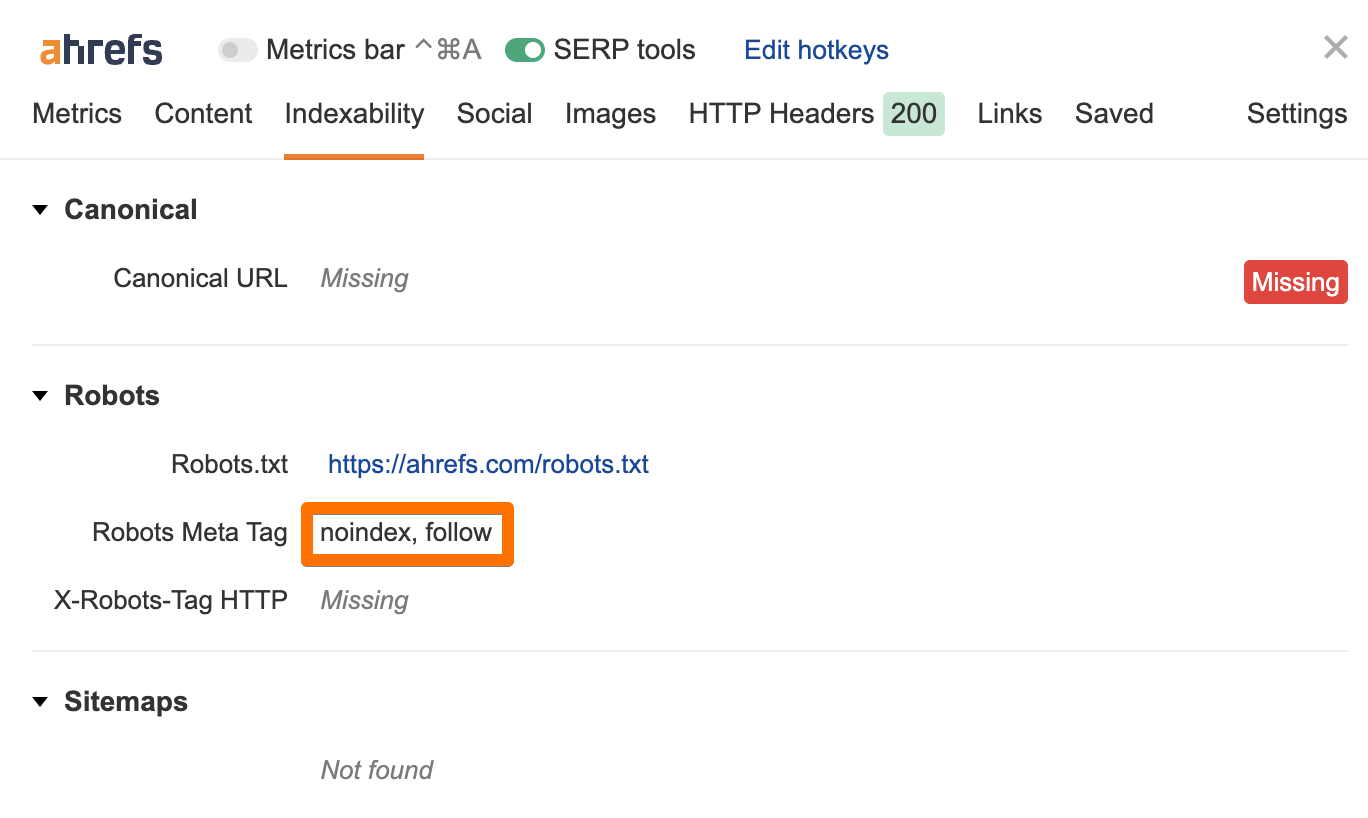
3. Use crawler directives wisely
Apart from robots.txt file, there are page-level directives that notify crawlers which pages are allowed (or not allowed) to be crawled.
Thus, you need to ensure that the pages you want to be indexed do not have a “noindex” directive. Similarly, make sure that they don’t have a “nofollow” directive if you want their outgoing links to be crawled too.
You can use our free SEO Toolbar for Chrome and Firefox to check the directives on your pages.
4. Provide internal links between pages
Another simple way to help a page get indexed faster is by linking it to another page that is already indexed. Since Googlebot re-crawls pages, it will find the internal link and crawl it quickly.
Apart from crawling, internal linking passes the so-called “link juice” to the pages, increasing their PageRank.
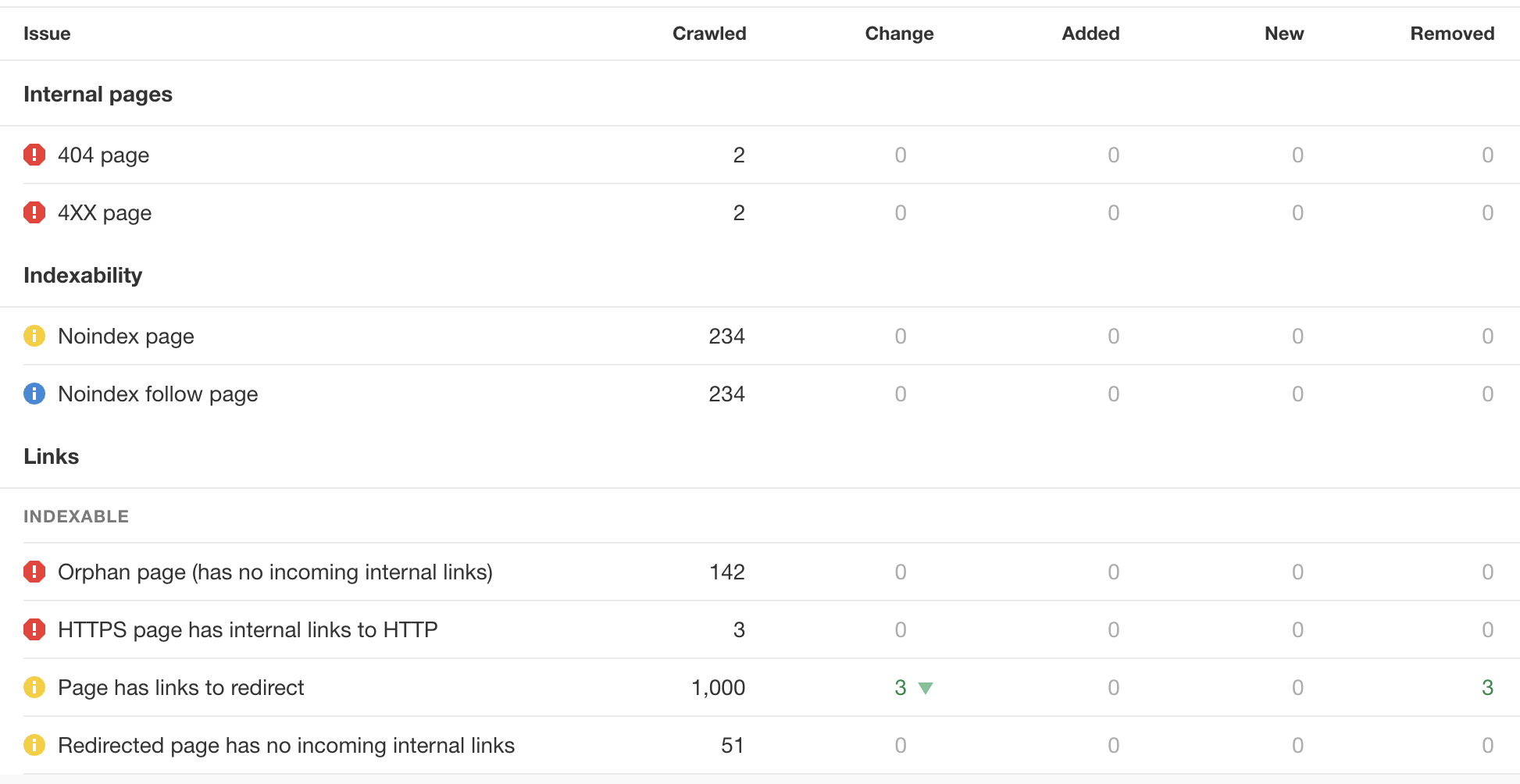
5. Use Site Audit to find crawlability and indexability issues
Lastly, you can use Ahrefs’ Site Audit tool to find issues related to indexability and crawlability on your websites.
The Site Audit can help you find broken pages, excessive redirects, redirect chains, noindex pages, nofollow links, orphan pages (those with no internal links), and more.
You can monitor your website’s SEO health for free with Ahrefs Webmaster tools.
FAQs
Is crawling and indexing the same thing?
No, the two aren’t the same. Crawling implies discovering pages and links on the web. Indexing refers to storing, analyzing, and organizing the content and connections between pages that were found while crawling.
It is only after a page is indexed that it is available to be displayed as a result for relevant queries.
Can I verify if a web crawler accessing my site is really Googlebot?
If you’re concerned that spammers or other troublemakers might be accessing your website claiming to be Googlebots, you can verify the crawler to see if it is actually a Google crawler.
Read this guide from Google to learn how to do that.
What is the main crawler for Googlebot?
Googlebot Smartphone is the primary crawler today.
User agent token:
Googlebot
Full user agent string:
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
The full list of Googlebot crawlers can be found here.