Cached Page
What is a Cached Page?
A cached page is a copy of a web page stored in temporary informational storage called “cache”.
The purpose of caching (storing and accessing data from a cache) is to store files to improve data retrieval performance. In short, caching ensures that future requests for the same data will be served faster.
It’s worth noting that there’s more than one type of cache - the two main types being server and browser caching.
On the user’s end, the browser will cache a page to ensure that it can display a web page faster without reloading the content from a server whenever the user revisits the particular web page or resource.
Then there’s something called server caching. CDNs - or Content Delivery Networks - will cache web content (images, videos, and webpages) in so-called “proxy servers” located closer to the end user than the website servers.
That said, search engines - such as Google - can also cache pages:
Google’s web crawlers regularly scour the web and index new sites. Throughout the process of crawling the web, the search engine also creates backups of web pages so that it can still show them to the user upon request - even if the live page is currently unavailable.
2024 Update: Google has removed the link to the cached pages from the SERPs.
Why are cached pages important?
In web browsers
When a user loads a particular web page, their browser has to download quite a bit of data to be able to display the page properly. However, with caching enabled, the server will store the HTML files, JavaScript, and images - essentially, a copy of that web page’s content - on the user’s hard drive.
That way, when the user loads the same page, there’s no need for the server to re-download the web documentation; the HTML file is already prepared and ready to be sent to the browser. That can, in turn, shorten load time and reduce bandwidth usage and server load.
In other words, caching allows the browser to display pages faster.
In CDNs
A CDN (Content Delivery Network) - CloudFlare, for example - will store copies of web pages on multiple different servers (also referred to as “proxy servers”) located throughout the world. That way, the CDN can deliver the requested content to the user from the nearest proxy server, which speeds things up significantly.
Here’s an example:
Suppose you’re in France and are visiting a site whose server is located in Australia. Loading a page from a server in France would be quicker than sending the request to a server in Australia - which is where caching comes in.
If the CDN has a copy (or cached page) of the page you requested on a proxy server in France, that is the one that will be used to process the user’s request and load the page.
In search engines
When Google processes the web page it just crawled, it takes a “screenshot” of sorts to act as a backup copy of that particular page. That way, the user can still access the cached page in case the live page they’re trying to access is temporarily unavailable or slow.
These pages are a part of Google’s cache, meaning you can view the cached version of a page directly from SERPs.
Click on the three dots (or a down arrow) next to the site’s URL in search results and select the “Cached” button in the “About this result” pop-up window, as shown below:
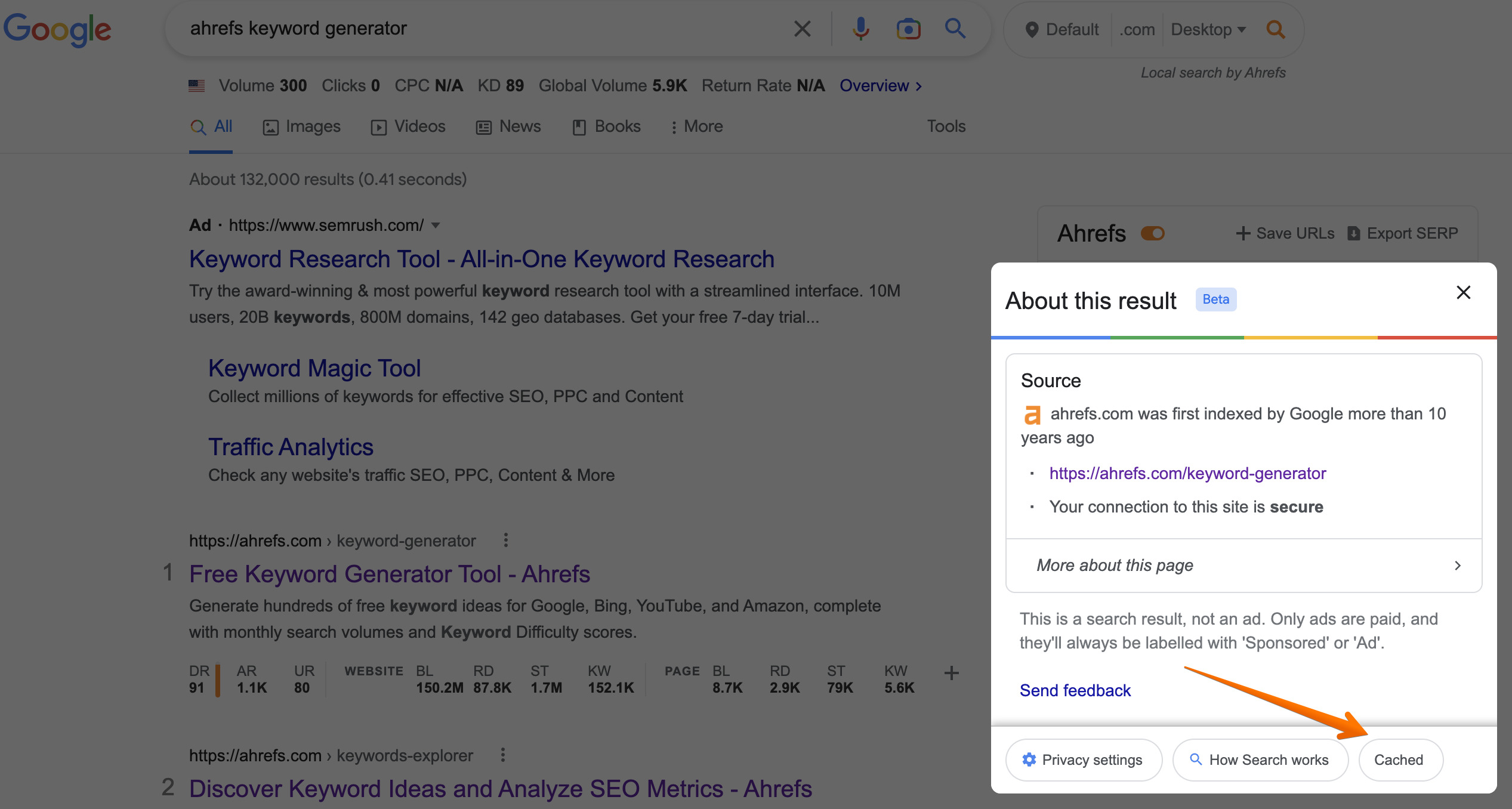
If you don’t want Google to display the cached versions of your web pages in SERPs, you can use Robots meta tags - and, more specifically, the Noarchive Tag - to prevent the search engine from caching your content.
You can generally use the following code snippet to add a Noarchive Tag to your web page:
<Meta name=“Robots” Content= “Noarchive”>
However, if you’re targeting Google’s crawlers, in particular, use this method:
<Meta Name= “GoogleBot” Content= “Noarchive”>