X-Robots-Tag
What is the X-Robots-Tag?
The X-Robots-Tag is an optional component of the HTTP response header of a URL. Much like the meta robots tag, it informs the search engines on how to crawl and index a web page.
However, there are some crucial differences between the two:
Unlike the robots meta tag (which is reserved for HTML pages), the X-Robots-Tags are used in the HTTP protocol response headers and can, therefore, be used for non-HTML files - such as images, text files, and PDF documents, too.
Here’s what the HTTP response with the X-Robots-Tag may look like:
HTTP/1.1 200 OK
Date: Tue, 15 Nov 2022 11:38:17 GMT
Content-encoding: gzip
(…)
X-Robots-Tag: noindex
(…)
The X-Robots-Tag may specify a user agent (crawler) and can use a comma-separated list of directives.
Example:
HTTP/1.1 200 OK
Date: Tue, 15 Nov 2022 11:38:17 GMT
Content-encoding: gzip
(…)
X-Robots-Tag: googlebot: noarchive, nofollow
(…)
Google first announced that it included support for the X-Robots-Tag directive in 2007 and made it clear that any directive used as a robots meta tag could also be used as an X-Robots-Tag.
Why is the X-Robots-Tag important?
X-Robots-Tag is important because it enables the use of regular expressions, executing crawler directives on non-HTML files, and applying parameters at a global, site-wide level. As such, it is a more flexible choice compared to the meta robots tag.
It’s worth noting that using an X-Robots-Tag generally isn’t as straightforward as using the meta robots tags - but since it allows you to direct search engines on how to index and crawl other file types, there are instances where it makes more sense to employ the X-Robots-Tag.
Here’s an example:
The most common way to instruct Google’s crawlers not to crawl or index page content is to use the meta robots tag found in the HTML code. But, when you want to instruct Google not to index specific text documents and other non-HTML files, an X-Robots-Tag is your only option.
In essence, X-Robots-Tags are a better choice if:
- You wish to use specific directives that apply to non-HTML files - including PDF files and images
- You wish to use directives at scale and deindex an entire subdomain or multiple web pages that match a certain parameter
What directives can be used in the X-Robots-Tag?
As mentioned in Google’s specifications, any directive that’s utilized in a robots meta tag can be employed as an X-Robots-Tag, as well.
The complete list of valid indexing and/or serving directives that are recognized by Google and can be used with the X-Robots-Tag is relatively long - but the most commonly used ones are:
- noindex - If you include this directive, you will instruct the search engine not to show the page, file, or media in SERPs.
- nofollow - If you include this directive, you will instruct the search engine crawlers not to follow the links found on the page or in a document.
- none - This directive is comparable to “noindex, nofollow.”
- noarchive - If you include this directive, you will instruct the search engine not to show the cached page in search results.
- nosnippet - If you include this directive, you will instruct the search engine not to show a snippet or preview of that page in search results.
You can find the full list of directives accepted by Google here.
How to set up the X-Robots-Tag?
You can include the X-Robots-Tag in a website’s HTTP responses using the configuration files of the website’s server.
On Apache, you can do so through the .htaccess file or httpd.conf file - and on NGINX, it can be done in the site’s .conf file.
Furthermore, you can combine several X-Robots-Tag directives in a comma-separated list. Here is an example of a combination of directives that will instruct Googlebot not to index URLs with a “.pdf” extension or follow any links on them:
<Files ~ "\.pdf$">
Header set X-Robots-Tag "noindex, nofollow"
</Files>
Adding the snippet of code shown above to the site’s root directory means that directive applies to any and all PDF files found on the website.
Also, when using an X-Robots-Tag in HTTP responses, you can appoint different instructions for different crawlers by specifying the crawler’s name.
If the bot (crawler) name isn’t specified, the directive applies to all crawlers by default. However, when a particular robot is specified - in this example, Googlebot - then the command will look like this:
Header set X-Robots-Tag "googlebot: noindex, nofollow"
There’s one crucial thing to remember when using the X-Robots-Tag:
Googlebot - or any other “good” web crawler - will only be able to read the X-Robots-Tag when it is able to access the URL. If you’ve disallowed crawling of a particular URL through the robots.txt file, then these indexing and/or serving directives will be ignored.
Where do I find the X-Robots-Tag?
Unlike the robots meta tag, the X-Robots-Tag cannot be found in the HTML code of a particular page. It’s an element of the HTTP response header - and, as such, can be trickier to read in the browser.
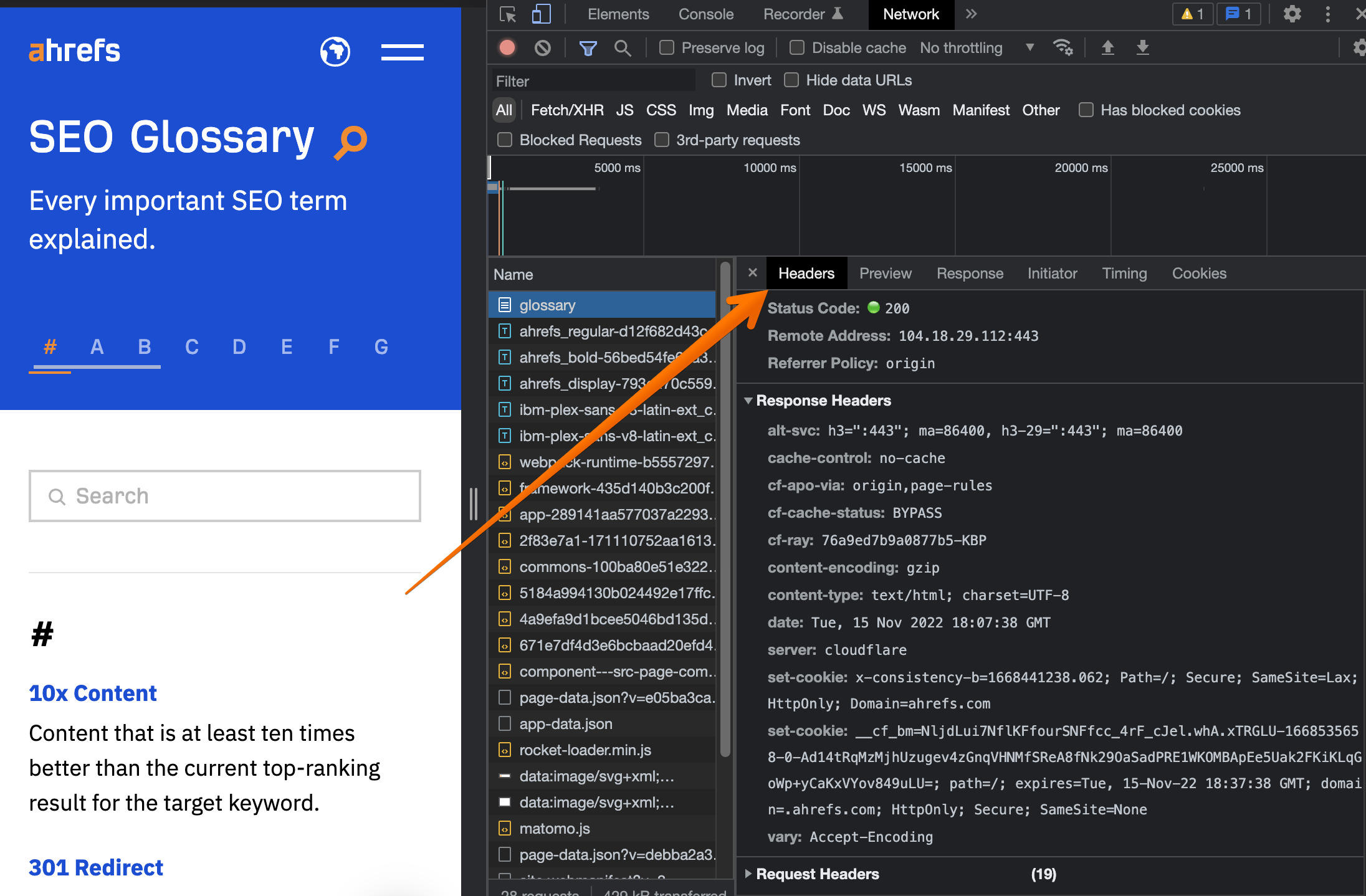
Here’s how you can view the HTTP response headers in Google Chrome:
- Load the desired URL in Google Chrome, right-click on the page, and select “Inspect” to access the developer tools.
- Select the “Network” tab.
- Reload the page, then select the necessary file displayed on the left side of the panel, and the HTTP headers information will be shown on the right side of the panel.
Our SEO Toolbar is a free browser extension available for Chrome and Firefox that simplifies that process. If present, the X-Robots-Tag of a certain URL will be displayed in the “Indexability” section.
