Crawler
What is a Crawler?
A crawler is an internet program designed to browse the internet systematically. Crawlers are most commonly used as a means for search engines to discover and process pages for indexing and showing them in the search results.
In addition to crawlers that process HTML, some special crawlers are also used for indexing images and videos.
In the real world, the main web crawlers to know are the ones used by the world’s top search engines: Googlebot, Bingbot, Yandex Bot, and Baidu Spider.
Good vs. Bad Crawlers
Think of a good crawler as a bot that can help your site, primarily by adding your content to a search index or by helping you audit your website.
Other hallmarks of a good crawler are that it identifies itself, follows your directives, and adjusts its crawling rate to keep from overloading your server.
A bad crawler is a bot that adds no value to a website owner and may have malicious intent.
Web properties communicate whether they want pages to be crawled and indexed through their robots.txt file and on-page directives. Still, a bad crawler may fail to identify itself, circumvent your directives, create unnecessary loads on servers, and even steal content and data.
Types of Crawlers
There are two main types of crawlers:
- Constant-crawling bots are performing a crawl 24/7 to discover new pages and recrawl older ones (e.g., Googlebot).
- On-demand bots will crawl a limited number of pages and perform a crawl only when requested (e.g., AhrefsSiteAudit bot).
Why is website crawling important?
So, why does web crawling matter?
In general, the purpose behind a search engine crawler is to find out what’s on your website and add this information to the search index. If your site isn’t crawled, then your content will not appear in the search results.
Website crawling isn’t just a one-time event – it’s an ongoing practice for active websites. Bots will regularly recrawl websites to find and add new pages to the search index while also updating their information about existing pages.
While most crawlers are associated with search engines, there are other types of crawlers out there. For example, the AhrefsSiteAudit bot, which powers our Site Audit tool, can help you see what’s wrong with your website in terms of SEO.
How do crawlers work?
Now that we’ve explored what crawlers are and why they’re important, let’s dive into how search engine crawlers actually work.
In a nutshell, a web crawler like Googlebot will discover URLs on your website through sitemaps, links, and manual submissions via Google Search Console. Then it will follow the “allowed” links on that pages.
It does this while respecting the robots.txt rules, as well as any “nofollow” attributes on links and on individual pages.
You should also note that some websites – those with more than 1 million pages that are updated regularly or those with 10 thousand pages of content that changes daily – may have a limited “crawl budget.”
Crawl budget refers to the amount of time and resources the bot can devote to a website in a single session.
Even though there is a lot of buzz around the crawl budget in SEO communities, the vast majority of website owners won’t have to worry about the crawl budget.
Crawl Priorities
Because of the limited capacity of crawl budgets, crawlers operate by a set of crawl priorities. Googlebot, for example, considers the following:
- PageRank of the URL
- How often the page(s) are updated
- Whether or not the page is new
In this way, the crawler can focus on crawling the most important pages on your site first.
Mobile vs. Desktop Crawler Versions
Googlebot, for example, has two main versions: Googlebot Desktop and Googlebot Smartphone.
These days, Google uses mobile-first indexing, which means that its smartphone agent is the primary Googlebot used for crawling and indexing pages.
Still, it’s important to understand that different versions of a website can be presented to these different types of crawlers.
Technically, the bot identifies itself to a web server using the HTTP request header User-Agent, along with a unique identifier.
User agent token:
Googlebot
Full user agent string:
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
For example, in the Ahrefs Site Audit tool, you can choose between the mobile and desktop versions of the crawler.
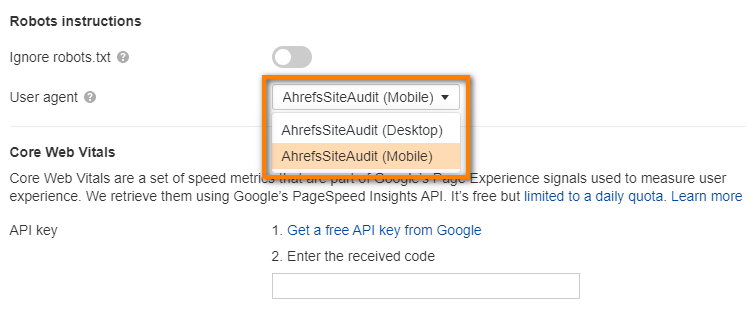
This allows you to ensure that both versions of your website are okay, and if not, helps you pinpoint any issues that may be specific for just mobile or just desktop.
Best practices for a crawl-friendly website
To ensure that your website is ready for crawling, there are several steps we recommend. Follow them in order to give your key pages the best chance of indexing and ranking.
1. Check your robots.txt file
Remember how crawlers are sometimes referred to as “bots?” Well, the robots.txt file is the file on your website that communicates with those bots, using a series of crawler directives.
The robots.txt file is located in the root directory of your website, which you can usually view by navigating to yourwebsite.com/robots.txt. To edit your robots.txt file, you’ll need an FTP client or access to your host’s cPanel.
Once inside the robots.txt file, you’ll want to ensure that it’s not disallowing good bots from any pages or sections that you want to be indexed.
If you understand the directives within a robots.txt, just viewing it will be enough to check for these errors, such as an incorrect noindex or nofollow directive.
Otherwise, you can use a robots.txt testing tool. For Googlebot specifically, you can use their robots.txt tester.
You should also make sure that robots.txt is accessible to crawlers – you don’t want it to be blocked on the server level.
2. Submit sitemaps
The next step is to submit your sitemap, which is a simple text file saved in XML format that lists all the pages of your website you want to be indexed.
If you want to submit the sitemap URL manually, this is what it looks like in Google Search Console under Index > Sitemaps:

The process will be similar for other popular search engines, such as within Bing Webmaster Tools.
Fortunately, creating sitemaps doesn’t have to be a complicated step. If your site runs on WordPress, any popular SEO plugin – such as Yoast or Rank Math – will automatically generate the sitemaps for you and provide the sitemap URLs for you to submit.
Typically, the URL will look something like this:
yourwebsite.com/sitemap_index.html
3. Use crawler directives wisely
The robots.txt file uses directives to tell crawlers which pages are allowed (or disallowed) to be crawled. Based on these rules in the robots.txt file, the crawler can visit a page that is “allowed” and check for further instructions, such as a “nofollow” meta tag in the
section of your HTML page or a “nofollow” link attribute in the page’s HTML code.With this in mind, it’s important that you allow important pages in your site’s navigation to be crawled. Any page-level directives won’t be seen if the content is disallowed to be crawled in your robots.txt file.
And even if you don’t want some of your pages to be indexed, they still play a key role in allowing the crawler to follow links and discover other pages on your site.
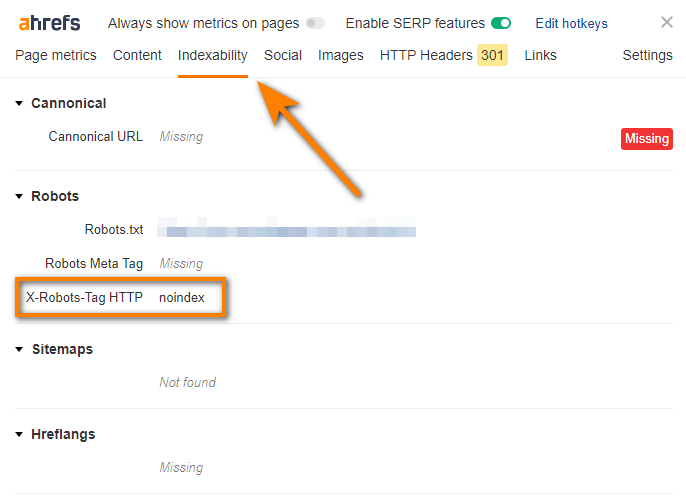
These directives can also be set in “X-Robots-Tag” HTTP headers, which is often overlooked.
You can easily read these headers with Ahrefs’ SEO Toolbar.
4. Provide internal links between pages
It’s difficult to overstate the importance of internal linking between pages on your site.
Not only does this help search engines understand what each page is about, but it also helps the crawler discover pages in the first place – this occurs when Googlebot follows a known page to a new page.
Internal links also help you shape how PageRank flows throughout your site. Typically, the more internal links you have pointing to a particular page, the more important it is.
5. Reduce 4xx’s and unnecessary redirects
Just like internal linking, technical SEO is an important – and often overlooked – factor in a website’s SEO profile.
As a quick reminder, 4xx errors essentially signal to a crawler that the content at that URL does not exist (404) or is not accessible (403). If you’ve taken down a page, for example, it will likely appear as a 404 page and eventually be removed from the search index.
Having an occasional 4xx error isn’t a big deal, but excessive 4xx status codes represent a lot of “dead ends” for a crawler. If the bot keeps finding dead or broken pages when it crawls your site, this will not be good for smooth crawling.
So, as much as you can, use Ahrefs Site Audit to fix these pages or set up a redirect to a live page.
You will also want to eliminate any unnecessary redirects and redirect chains. Every redirect represents a new server request, which means slower-loading pages and an inferior user experience.
Some redirects are required – such as from pages you’ve taken down – but use them only when necessary.
6. Use Ahrefs Site Audit to find crawlability and indexability issues
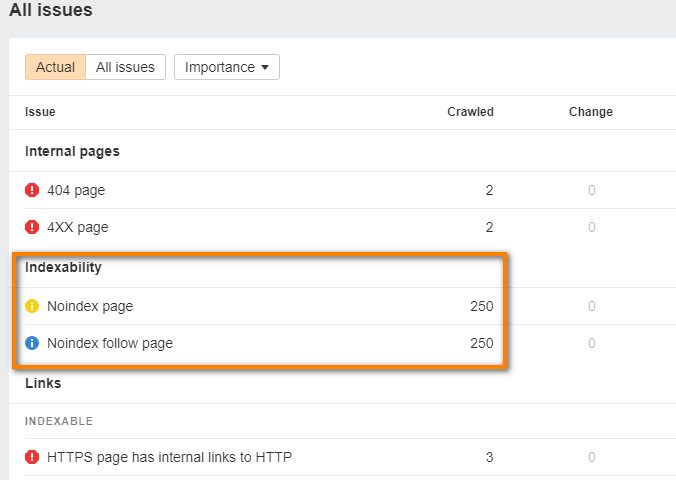
The Ahrefs Site Audit tool can help by checking all noindexed pages and nofollowed links on your site. At a glance, you’ll be able to see if the correct pages on your site are accessible.
In addition, Site Audit can uncover any broken pages or excessive redirects, including redirect chains or loops. It can also point out any orphan pages – these are pages that don’t have any incoming internal links.
You can use this tool on your site as well. If you don’t have an Ahrefs subscription, the Ahrefs Site Audit is available for free within Ahrefs Webmaster Tools.
FAQs
Is crawling and indexing the same thing?
No. Crawling refers to the process of discovering publicly accessible web pages and other content. Indexing refers to search engines analyzing these pages and storing them in their search index.
What are the most active crawlers?
We mentioned several of the most popular search engine crawlers earlier, including Googlebot, Bingbot, Yandex Bot, and Baidu spider.
To learn more about active crawlers, check out this Imperva Bot Traffic study. Interestingly, AhrefsBot, which powers our entire link database, was found to be the second most active crawler after Googlebot.
Do crawlers hurt my website?
While most crawlers do not pose harm to your website, there are bad crawlers that can.
Most often, a harmful crawler will hog your bandwidth, causing pages to slow down and hurting your site’s user experience. However, a bad bot may also attempt to steal data or scrape content from your site.